Redis布隆过滤器(原理+图解)
布隆过滤器(Bloom Filter)是 Redis 4.0 版本提供的新功能,它被作为插件加载到 Redis 服务器中,给 Redis 提供强大的去重功能。
相比于 Set 集合的去重功能而言,布隆过滤器在空间上能节省 90% 以上,但是它的不足之处是去重率大约在 99% 左右,也就是说有 1% 左右的误判率,这种误差是由布隆过滤器的自身结构决定的。俗话说“鱼与熊掌不可兼得”,如果想要节省空间,就需要牺牲 1% 的误判率,而且这种误判率,在处理海量数据时,几乎可以忽略。
下面举两个简单的例子:
布隆过滤器使用
下面对布隆过滤器工作流程做简单描述,如下图所示:
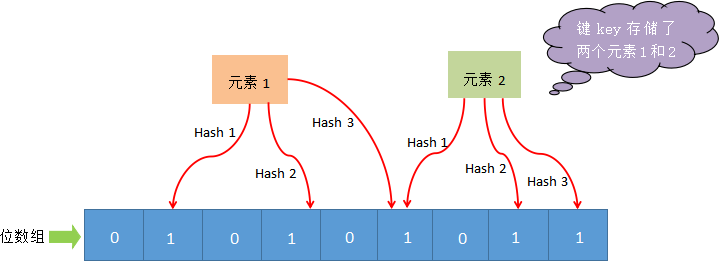
图1:布隆过滤器原理
当使用布隆过滤器添加 key 时,会使用不同的 hash 函数对 key 存储的元素值进行哈希计算,从而会得到多个哈希值。根据哈希值计算出一个整数索引值,将该索引值与位数组长度做取余运算,最终得到一个位数组位置,并将该位置的值变为 1。每个 hash 函数都会计算出一个不同的位置,然后把数组中与之对应的位置变为 1。通过上述过程就完成了元素添加(add)操作。
注意:如果要使用自定义的布隆过滤器需要在 add 操作之前,使用 bf.reserve 命令显式地创建 key,格式如下:
相比于 Set 集合的去重功能而言,布隆过滤器在空间上能节省 90% 以上,但是它的不足之处是去重率大约在 99% 左右,也就是说有 1% 左右的误判率,这种误差是由布隆过滤器的自身结构决定的。俗话说“鱼与熊掌不可兼得”,如果想要节省空间,就需要牺牲 1% 的误判率,而且这种误判率,在处理海量数据时,几乎可以忽略。
应用场景
布隆过滤器是 Redis 的高级功能,虽然这种结构的去重率并不完全精确,但和其他结构一样都有特定的应用场景,比如当处理海量数据时,就可以使用布隆过滤器实现去重。下面举两个简单的例子:
1) 示例:
百度爬虫系统每天会面临海量的 URL 数据,我们希望它每次只爬取最新的页面,而对于没有更新过的页面则不爬取,因策爬虫系统必须对已经抓取过的 URL 去重,否则会严重影响执行效率。但是如果使用一个 set(集合)去装载这些 URL 地址,那么将造成资源空间的严重浪费。2) 示例:
垃圾邮件过滤功能也采用了布隆过滤器。虽然在过滤的过程中,布隆过滤器会存在一定的误判,但比较于牺牲宝贵的性能和空间来说,这一点误判是微不足道的。工作原理
布隆过滤器(Bloom Filter)是一个高空间利用率的概率性数据结构,由二进制向量(即位数组)和一系列随机映射函数(即哈希函数)两部分组成。布隆过滤器使用
exists()来判断某个元素是否存在于自身结构中。当布隆过滤器判定某个值存在时,其实这个值只是有可能存在;当它说某个值不存在时,那这个值肯定不存在,这个误判概率大约在 1% 左右。1) 工作流程-添加元素
布隆过滤器主要由位数组和一系列 hash 函数构成,其中位数组的初始状态都为 0。下面对布隆过滤器工作流程做简单描述,如下图所示:
图1:布隆过滤器原理
当使用布隆过滤器添加 key 时,会使用不同的 hash 函数对 key 存储的元素值进行哈希计算,从而会得到多个哈希值。根据哈希值计算出一个整数索引值,将该索引值与位数组长度做取余运算,最终得到一个位数组位置,并将该位置的值变为 1。每个 hash 函数都会计算出一个不同的位置,然后把数组中与之对应的位置变为 1。通过上述过程就完成了元素添加(add)操作。
2) 工作流程-判定元素是否存在
当我们需要判断一个元素是否存时,其流程如下:首先对给定元素再次执行哈希计算,得到与添加元素时相同的位数组位置,判断所得位置是否都为 1,如果其中有一个为 0,那么说明元素不存在,若都为 1,则说明元素有可能存在。3) 为什么是可能“存在”
您可能会问,为什么是有可能存在?其实原因很简单,那些被置为 1 的位置也可能是由于其他元素的操作而改变的。比如,元素1 和 元素2,这两个元素同时将一个位置变为了 1(图1所示)。在这种情况下,我们就不能判定“元素 1”一定存在,这是布隆过滤器存在误判的根本原因。安装与使用
在 Redis 4.0 版本之后,布隆过滤器才作为插件被正式使用。布隆过滤器需要单独安装,下面介绍安装 RedisBloom 的几种方法:1) docker安装
docker 安装布隆过滤器是最简单、快捷的一种方式:docker pull redislabs/rebloom:latest docker run -p 6379:6379 --name redis-redisbloom redislabs/rebloom:latest docker exec -it redis-redisbloom bash redis-cli #测试是否安装成功 127.0.0.1:6379> bf.add www.biancheng.net hello
2) 直接编译安装
如果您对 docker 不熟悉,也可以采用直接编译的方式来安装。下载地址: https://github.com/RedisBloom/RedisBloom 解压文件: unzip RedisBloom-master.zip 进入目录: cd RedisBloom-master 执行编译命令,生成redisbloom.so 文件: make 拷贝至指定目录: cp redisbloom.so /usr/local/redis/bin/redisbloom.so 在redis配置文件里加入以下配置: loadmodule /usr/local/redis/bin/redisbloom.so 配置完成后重启redis服务: sudo /etc/init.d/redis-server restart #测试是否安装成功 127.0.0.1:6379> bf.add www.biancheng.net hello
常用命令汇总
| 命令 | 说明 |
|---|---|
| bf.add | 只能添加元素到布隆过滤器。 |
| bf.exists | 判断某个元素是否在于布隆过滤器中。 |
| bf.madd | 同时添加多个元素到布隆过滤器。 |
| bf.mexists | 同时判断多个元素是否存在于布隆过滤器中。 |
| bf.reserve | 以自定义的方式设置布隆过滤器参数值,共有 3 个参数分别是 key、error_rate(错误率)、initial_size(初始大小)。 |
1) 命令应用
127.0.0.1:6379> bf.add spider:url www.biancheng.net (integer) 1 127.0.0.1:6379> bf.exists spider:url www.biancheng.net (integer) 1 127.0.0.1:6379> bf.madd spider:url www.taobao.com www.123qq.com 1) (integer) 1 2) (integer) 1 127.0.0.1:6379> bf.mexists spider:url www.jd.com www.taobao.com 1) (integer) 0 2) (integer) 1
Python使用布隆过滤器
下面使用 Python 测试布隆过滤器的误判率,代码如下所示:
import redis
size=10000
r = redis.Redis()
count = 0
for i in range(size):
#添加元素,key为userid,值为user0...user9999
r.execute_command("bf.add", "userid", "user%d" % i)
#判断元素是否存在,此处切记 i+1
res = r.execute_command("bf.exists", "userid", "user%d" % (i + 1))
if res == 1:
print(i)
count += 1
#求误判率,round()中的5表示保留的小数点位数
print("size: {} ,error rate:{}%".format(size, round(count / size * 100, 5)))
执行三次测试,size 从小到大。输出结果如下:
size: 1000 , error rate: 1.0% size: 10000 , error rate: 1.25% size: 100000 , error rate: 1.305%通过上述结果可以看出布隆过滤器的错误率为 1% 多点,当 size 越来越大时,布隆过滤器的错误率就会升高,那么有没有办法降低错误率呢?这就用到了布隆过滤器提供的
bf.reserve方法。如果不使用该方法设置参数,那么布隆过滤器将按照默认参数进行设置,如下所示:
key #指定存储元素的键,若已经存在,则bf.reserve会报错 error_rate=0.01 #表示错误率 initial_size=100 #表示预计放入布隆过滤器中的元素数量当放入过滤器中的元素数量超过了 initial_size 值时,错误率 error_rate 就会升高。因此就需要设置一个较大 initial_size 值,避免因数量超出导致的错误率上升。
解决错误率过高的问题
错误率越低,所需要的空间也会越大,因此就需要我们尽可能精确的估算元素数量,避免空间的浪费。我们也要根据具体的业务来确定错误率的许可范围,对于不需要太精确的业务场景,错误率稍微设置大一点也可以。注意:如果要使用自定义的布隆过滤器需要在 add 操作之前,使用 bf.reserve 命令显式地创建 key,格式如下:
client.execute_command("bf.reserve", "keyname", 0.001, 50000)
布隆过滤器相比于平时常用的的列表、散列、集合等数据结构,其占用空间更少、效率更高,但缺点就是返回的结果具有概率性,并不是很准确。在理论情况下,添加的元素越多,误报的可能性就越大。再者,存放于布隆过滤器中的元素不容易被删除,因为可能出现会误删其他元素情况。